
Written by Michael Yang, AI/ML Big Data Architect Lead & Daan Grashoff, AI/ML Engineer
The rapid advancement of Generative AI has sparked considerable buzz in the media and business world, and companies are eager to adopt GenAI capabilities to enhance their products and services. However, the lightning speed at which this technology is developing presents new obstacles that are difficult to identify and address. Questions around data security, privacy, infrastructure management, and the complexities of model alignment and deployment are major hindrances to effectively adopting GenAI.
Amazon’s Bedrock aims to tackle these challenges. With the release of Amazon’s Bedrock, organizations of any size will be able to explore, build, and deploy Generative AI models at scale while maintaining data security and privacy. This blog will explore how customers can use AWS Bedrock to streamline their Generative AI projects.
Define Use Case
For our example, we will create a QA chatbot to assist in onboarding new employees. This chatbot enables new hires to directly seek answers from the resources available on Confluence.
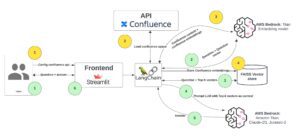
Outlined below are the steps that correspond to the numbers within the architecture diagram:
Initial setup in yellow (occurs once):
- Users input their username, Confluence API key, space, and Confluence wiki URL.
- LangChain interfaces with the Confluence API, fetching and dividing all pages into smaller chunks from the specified space.
- Confluence content chunks will be embedded using the AWS Bedrock Titan embedding services.
- Embeddings are stored in the FAISS vector database.
Interaction for new hires in green:
- Users use the Streamlit interface to ask questions related to the onboarding process, HR, or general company queries.
- LangChain will use AWS Bedrock to embed the question.
- LangChain uses question embeddings to retrieve the top-k vectors containing potential answers.
- Using the prompt template, top-k contexts, and the question, LangChain prompts the AWS Bedrock language model.
- AWS Bedrock provides answers through its API.
- Streamlit displays the answers and pertinent contexts. These contexts are directly connected to the original Confluence Space Page and can be accessed directly through the attached URL.
Model Selection
Foundational Models
AWS Bedrock aims to accelerate the development of generative AI applications by offering FMs through an API, without managing infrastructure. AWS Bedrock supports the following FMs:
-
- AWS Titan (Amazon): Generative large language model (LLM) for tasks such as summarization, text generation, classification, open-ended Q&A, and information extraction
- Jurassic (AI21labs): Multilingual LLMs for text generation in Spanish, French, German, Portuguese, Italian, and Dutch
- Claude (ANTROPIC): LLM for conversations, question answering, and workflow automation based on research into training honest and responsible AI systems.
- Stable Diffusion (StabilityAI): Generation of unique realistic, high-quality images, art, logos, and designs
Data Privacy and Localization
AWS Bedrock does not use customer data to improve the Amazon Titan for other customers nor is data shared with other foundational model providers. In addition, customer data (prompts, responses, fine-tuned models) are isolated per customer and remain in the Region where they were created.
Data and Model Security
For data encryption, customer data is always encrypted in transit with a minimum of TLS1.2 and AE-256 encrypted at rest using AWS KMS-managed data encryption keys. Fine-tuned (customized) models are encrypted and stored using the customer AWS KMS key.
Users can use AWS Identity and Access Management Service (IAM) to manage inference access and allow/deny access for specific models. AWS CloudTrail is used to monitor all API activity and troubleshoot suspicious activity.
Example Use Case
We will use AWS Titan for our foundational model given its capabilities for open-ended Q&A and information extraction, aligning with our use case of a QA bot to answer onboarding questions. You can find the detailed solution in the following link.
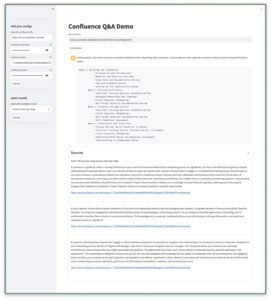
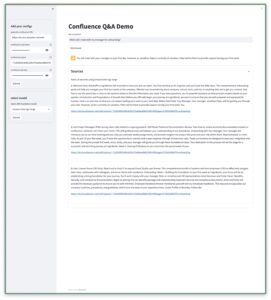
Evaluation
For our evaluation, we curated 60 HR-related questions and used human judgment to interpret the generated answers from LLM. The criteria for a good answer must be factual, coherent, and non-toxic. The result shows that 94% of the answers were valid.
Conclusion
We’re ending this blog with some tips to elevate your QA experience.
- Prompt Template Experimentation: Engage in thoughtful prompt engineering. The prompt is pivotal for an effective QA/chatbot application. Explore zero-shot, one-shot, or few-shot prompts to tailor the interaction.
- Quality Context: Remember, the output quality relies on the input data quality. Complete, accurate context is essential for generating reliable responses.
- Fine-tune Model Parameters: Delve into additional AWS Bedrock model parameters like temperature, topP, and stop sequences to calibrate responses.
- Customize for Use Cases: Tailor the prompt template to the specific use case. Whether it’s step-by-step guides or other formats, adapt the template to your expectations.